Example 3: Deep Formulas
The orignal Kolmogorov-Arnold theorem says that it suffices to have 2-Layer function composition (inner and outer functions), but the functions might be non-smooth or even fractal. We generalize KA representation to arbitrary depths. An example a 2-Layer KAN (with smooth activations) is unable to do is: \(f(x_1,x_2,x_3,x_4)={\rm exp}({\rm sin}(x_1^2+x_2^2)+{\rm sin}(x_3^2+x_4^2))\), which requires at least 3-Layer KANs.
Three-layer KAN
from kan import *
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# create a KAN: 2D inputs, 1D output, and 5 hidden neurons. cubic spline (k=3), 5 grid intervals (grid=5).
model = KAN(width=[4,2,1,1], grid=3, k=3, seed=1, device=device)
f = lambda x: torch.exp((torch.sin(torch.pi*(x[:,[0]]**2+x[:,[1]]**2))+torch.sin(torch.pi*(x[:,[2]]**2+x[:,[3]]**2)))/2)
dataset = create_dataset(f, n_var=4, train_num=3000, device=device)
# train the model
model.fit(dataset, opt="LBFGS", steps=20, lamb=0.002, lamb_entropy=2.);
cuda
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 1.76e-02 | test_loss: 1.79e-02 | reg: 1.05e+01 | : 100%|█| 20/20 [00:05<00:00, 3.60it
saving model version 0.1
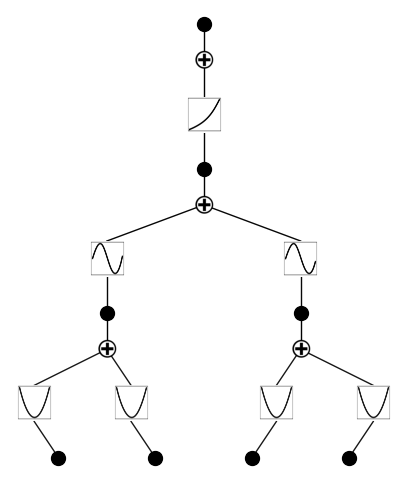
model = model.prune(edge_th=1e-2)
saving model version 0.2
model.plot()
grids = [3,5,10,20,50]
#grids = [5]
train_rmse = []
test_rmse = []
for i in range(len(grids)):
#model = KAN(width=[4,2,1,1], grid=grids[i], k=3, seed=0, device=device).initialize_from_another_model(model, dataset['train_input'])
model = model.refine(grid=grids[i])
results = model.fit(dataset, opt="LBFGS", steps=50, stop_grid_update_step=20);
train_rmse.append(results['train_loss'][-1].item())
test_rmse.append(results['test_loss'][-1].item())
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 9.21e-03 | test_loss: 9.23e-03 | reg: 1.04e+01 | : 100%|█| 50/50 [00:10<00:00, 4.89it
saving model version 0.1
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 3.33e-03 | test_loss: 3.25e-03 | reg: 1.05e+01 | : 100%|█| 50/50 [00:10<00:00, 4.72it
saving model version 0.1
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 1.13e-03 | test_loss: 1.07e-03 | reg: 1.04e+01 | : 100%|█| 50/50 [00:09<00:00, 5.33it
saving model version 0.1
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 3.93e-04 | test_loss: 3.75e-04 | reg: 1.04e+01 | : 100%|█| 50/50 [00:05<00:00, 9.74it
saving model version 0.1
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 3.60e-05 | test_loss: 3.78e-05 | reg: 1.04e+01 | : 100%|█| 50/50 [00:04<00:00, 10.01it
saving model version 0.1
Author’s note: The scaling isn’t optimal. Possibly because of updates on curve2coef, to be investigated.
import numpy as np
import matplotlib.pyplot as plt
n_params = np.array(grids) * (4*2+2*1+1*1)
plt.plot(n_params, train_rmse, marker="o")
plt.plot(n_params, test_rmse, marker="o")
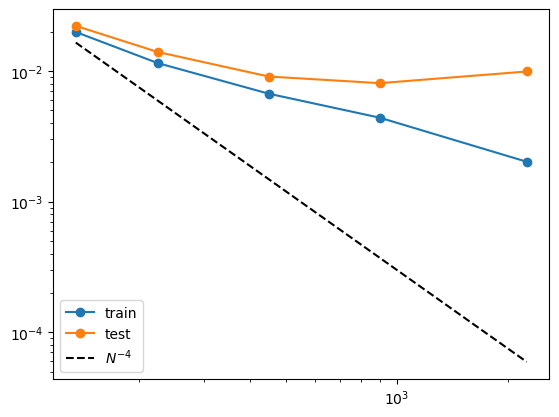
plt.plot(n_params, 10000*n_params**(-4.), color="black", ls="--")
plt.legend(['train', 'test', r'$N^{-4}$'], loc="lower left")
plt.xscale('log')
plt.yscale('log')
print(train_rmse)
print(test_rmse)
[0.009214929305016994, 0.0033308672718703747, 0.00112761405762285, 0.0003925061319023371, 3.601737262215465e-05]
[0.009230277501046658, 0.0032473765313625336, 0.0010660917032510042, 0.0003754299250431359, 3.784598084166646e-05]
Two-layer KAN
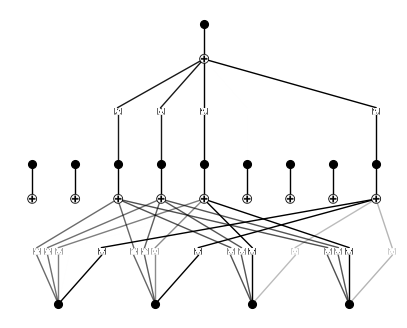
Now we show that a 2 two-layer KAN performs much worse for this task
from kan import KAN, create_dataset
import torch
# create a KAN: 2D inputs, 1D output, and 5 hidden neurons. cubic spline (k=3), 5 grid intervals (grid=5).
model = KAN(width=[4,9,1], grid=3, k=3, seed=0)
f = lambda x: torch.exp((torch.sin(torch.pi*(x[:,[0]]**2+x[:,[1]]**2))+torch.sin(torch.pi*(x[:,[2]]**2+x[:,[3]]**2)))/2)
dataset = create_dataset(f, n_var=4, train_num=3000)
# train the model
model.fit(dataset, opt="LBFGS", steps=20, lamb=0.002, lamb_entropy=2.);
model.plot(beta=10)
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 5.98e-02 | test_loss: 6.11e-02 | reg: 1.25e+01 | : 100%|█| 20/20 [00:08<00:00, 2.35it
saving model version 0.1
grids = [3,5,10,20,50]
train_rmse = []
test_rmse = []
for i in range(len(grids)):
#model = KAN(width=[4,9,1], grid=grids[i], k=3, seed=0).initialize_from_another_model(model, dataset['train_input'])
model = model.refine(grid=grids[i])
results = model.fit(dataset, opt="LBFGS", steps=50, stop_grid_update_step=30);
train_rmse.append(results['train_loss'][-1].item())
test_rmse.append(results['test_loss'][-1].item())
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 1.98e-02 | test_loss: 2.21e-02 | reg: 1.70e+01 | : 100%|█| 50/50 [00:15<00:00, 3.23it
saving model version 0.1
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 1.15e-02 | test_loss: 1.40e-02 | reg: 1.71e+01 | : 100%|█| 50/50 [00:13<00:00, 3.75it
saving model version 0.1
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 6.69e-03 | test_loss: 9.05e-03 | reg: 1.72e+01 | : 100%|█| 50/50 [00:13<00:00, 3.69it
saving model version 0.1
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 4.38e-03 | test_loss: 8.05e-03 | reg: 1.73e+01 | : 100%|█| 50/50 [00:15<00:00, 3.17it
saving model version 0.1
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 2.02e-03 | test_loss: 9.89e-03 | reg: 1.73e+01 | : 100%|█| 50/50 [00:17<00:00, 2.88it
saving model version 0.1
import numpy as np
import matplotlib.pyplot as plt
n_params = np.array(grids) * (4*9+9*1)
plt.plot(n_params, train_rmse, marker="o")
plt.plot(n_params, test_rmse, marker="o")
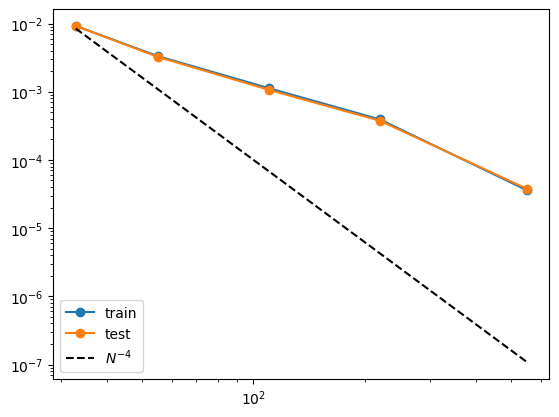
plt.plot(n_params, 300*n_params**(-2.), color="black", ls="--")
plt.legend(['train', 'test', r'$N^{-4}$'], loc="lower left")
plt.xscale('log')
plt.yscale('log')
print(train_rmse)
print(test_rmse)
[0.01983197219669819, 0.01147659495472908, 0.006687900051474571, 0.004380852449685335, 0.002016218611970544]
[0.022097894921898842, 0.013952379114925861, 0.009049860760569572, 0.008054238744080067, 0.00989140197634697]