Example 1: Function Fitting
In this example, we will cover how to leverage grid refinement to maximimze KANs’ ability to fit functions
intialize model and create dataset
from kan import *
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# initialize KAN with G=3
model = KAN(width=[2,1,1], grid=3, k=3, seed=1, device=device)
# create dataset
f = lambda x: torch.exp(torch.sin(torch.pi*x[:,[0]]) + x[:,[1]]**2)
dataset = create_dataset(f, n_var=2, device=device)
cuda
checkpoint directory created: ./model
saving model version 0.0
Train KAN (grid=3)
model.fit(dataset, opt="LBFGS", steps=20);
| train_loss: 4.16e-02 | test_loss: 4.35e-02 | reg: 9.79e+00 | : 100%|█| 20/20 [00:03<00:00, 6.03it
saving model version 0.1
The loss plateaus. we want a more fine-grained KAN!
# initialize a more fine-grained KAN with G=10
model = model.refine(10)
saving model version 0.2
Train KAN (grid=10)
model.fit(dataset, opt="LBFGS", steps=20);
| train_loss: 6.96e-03 | test_loss: 6.10e-03 | reg: 9.75e+00 | : 100%|█| 20/20 [00:02<00:00, 7.32it
saving model version 0.3
The loss becomes lower. This is good! Now we can even iteratively making grids finer.
grids = np.array([3,10,20,50,100])
train_losses = []
test_losses = []
steps = 200
k = 3
for i in range(grids.shape[0]):
if i == 0:
model = KAN(width=[2,1,1], grid=grids[i], k=k, seed=1, device=device)
if i != 0:
model = model.refine(grids[i])
results = model.fit(dataset, opt="LBFGS", steps=steps)
train_losses += results['train_loss']
test_losses += results['test_loss']
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 1.46e-02 | test_loss: 1.53e-02 | reg: 8.83e+00 | : 100%|█| 200/200 [00:10<00:00, 19.67
saving model version 0.1
saving model version 0.2
| train_loss: 2.84e-04 | test_loss: 3.29e-04 | reg: 8.84e+00 | : 100%|█| 200/200 [00:15<00:00, 13.09
saving model version 0.3
saving model version 0.4
| train_loss: 4.21e-05 | test_loss: 4.04e-05 | reg: 8.84e+00 | : 100%|█| 200/200 [00:09<00:00, 21.22
saving model version 0.5
saving model version 0.6
| train_loss: 1.02e-05 | test_loss: 1.24e-05 | reg: 8.84e+00 | : 100%|█| 200/200 [00:10<00:00, 18.76
saving model version 0.7
saving model version 0.8
| train_loss: 1.64e-04 | test_loss: 1.74e-03 | reg: 8.86e+00 | : 100%|█| 200/200 [00:17<00:00, 11.72
saving model version 0.9
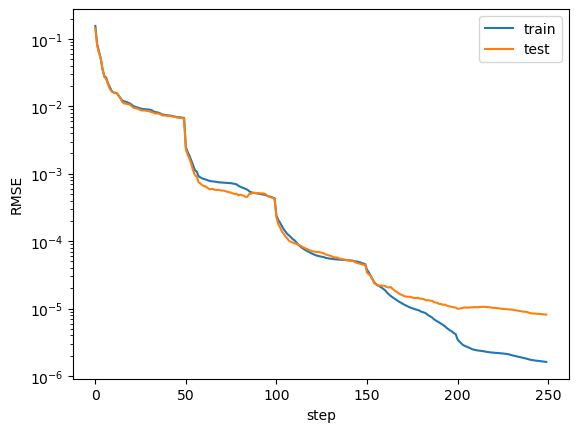
Training dynamics of losses display staircase structures (loss suddenly drops after grid refinement)
plt.plot(train_losses)
plt.plot(test_losses)
plt.legend(['train', 'test'])
plt.ylabel('RMSE')
plt.xlabel('step')
plt.yscale('log')
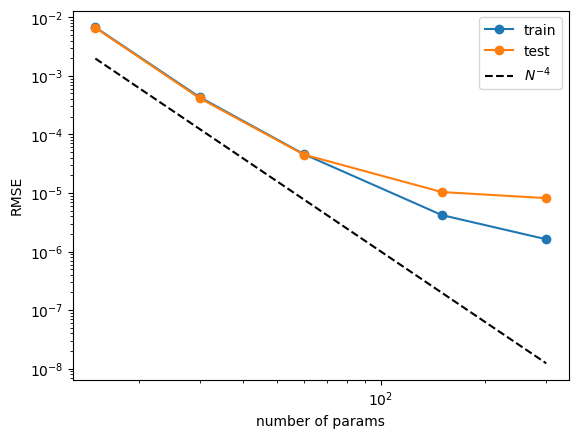
Neural scaling laws (For some reason, this got worse than pykan 0.0. We’re still investigating the reason, probably due to the updates of curve2coef)
n_params = 3 * grids
train_vs_G = train_losses[(steps-1)::steps]
test_vs_G = test_losses[(steps-1)::steps]
plt.plot(n_params, train_vs_G, marker="o")
plt.plot(n_params, test_vs_G, marker="o")
plt.plot(n_params, 100*n_params**(-4.), ls="--", color="black")
plt.xscale('log')
plt.yscale('log')
plt.legend(['train', 'test', r'$N^{-4}$'])
plt.xlabel('number of params')
plt.ylabel('RMSE')
Text(0, 0.5, 'RMSE')