Grokking in loss doesn't necessarily imply grokking in accuracy
Black: Agent generated; Red: Added by human
Introduction
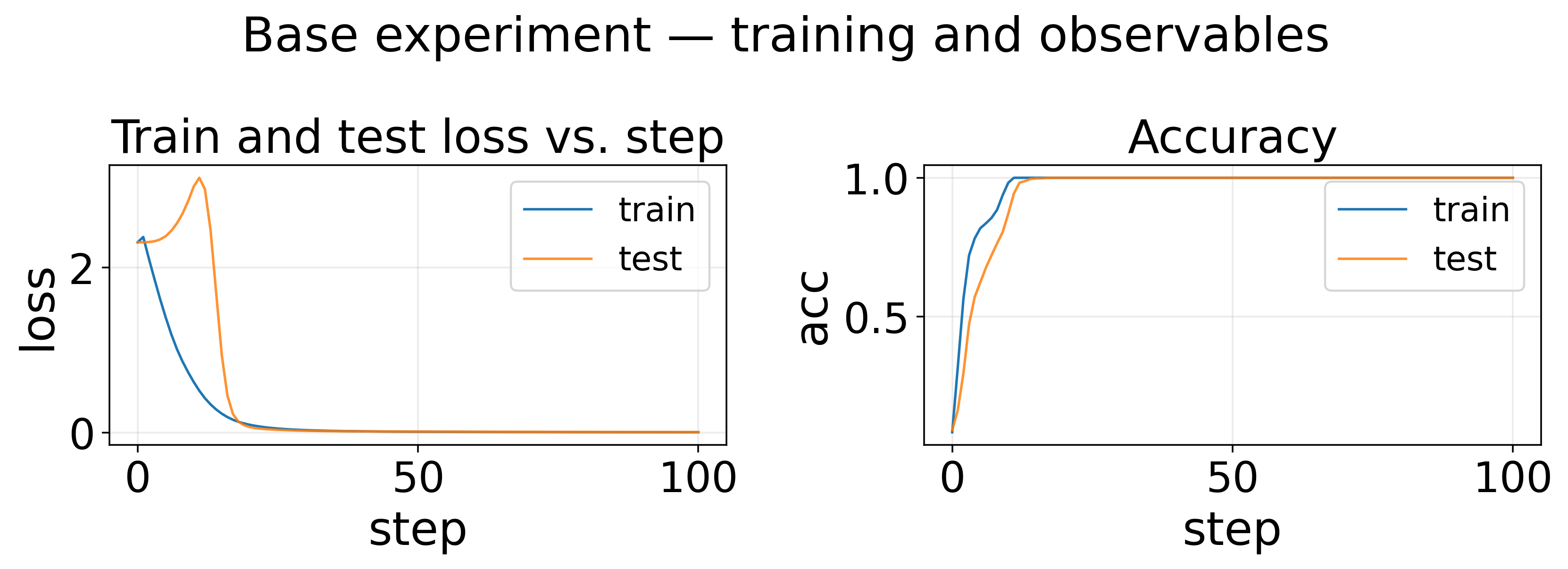
The original grokking paper shows a clear delayed generation in both loss and accuracy (especially accuracy), called grokking. In this blog, we aim to provide an example where loss curves have delayed generalization, but accuracy curves do not.
Experimental setup
Dataset: gaussian_blob_dataset — Multi-class toy vision data on tensors ( configurable, default 28). # classes sets with labels ; each class is a smooth 2D Gaussian blob at a grid cell inside the canvas. noise level adds per-pixel Gaussian noise (prototype jitter scales with the same knob). Generated locally—useful for MNIST-shaped training loops without IDX downloads or for quick MLP/ResNet sanity checks.
Parameters: flattenOutput=false, imageSize=28, initSeed=0, noiseLevel=0.15, numClasses=10, paramOrder=[numClasses, imageSize, noiseLevel, flattenOutput, samplingMode, trainSize, testSize, initSeed], samplingMode=fixed, seed=0, specCodeName=gaussian_blob_datasetSpec, testSize=512, trainSize=512
Model: resnet_model — Small ResNet-style CNN for 1×H×W inputs; use with vision datasets + cross-entropy.
Parameters: baseChannels=8, blocksStage1=2, blocksStage2=2, blocksStage3=2, blocksStage4=2, kernelSize=3, seed=3, specCodeName=resnetModelSpec, variant=self_defined
Optimizer: adam_optimizer — Adaptive moment estimation with first- and second-moment running averages. beta1 controls momentum of the gradient mean; beta2 controls momentum of the squared-gradient estimate. epsilon is a small numerical stabilizer in the denominator. weight decay is PyTorch’s L2 penalty coefficient on parameters (0 disables). Optional lr schedule input: one socket — lr_schedule (warmup / cosine) and mup_lr_schedule (layer-wise μP multipliers, Adam + supported models) each attach to the same port; you can wire either, both, or neither.
Parameters: beta1=0.9, beta2=0.999, epsilon=1e-08, learningRate=0.001, weightDecay=0
Loss: cross_entropy_loss — Cross-entropy for classification (e.g. token prediction).
Parameters: labelSmoothing=0, lossMaskContextLength=1, lossMaskCustom=, lossMaskMode=all, lossScale=1
Observables wired to training: observable_accuracy — Accuracy — classification accuracy on the train (and test when available) batch used for logging.
Trainer: trainer — Training loop: datasets, model, optimizer, loss, and observables.
Parameters: batchSize=-1, computeDevice=auto, gradClipMaxNorm=0, logFrequency=1, memoryCheckpoint_b64=(large value omitted), trainingSteps=100, vibeSurrogate=null
Base experiment — training and observables
Sweep experiments
Sweep: noise level 0.0, 0.15, 0.3
Sweep: noise level — Loss
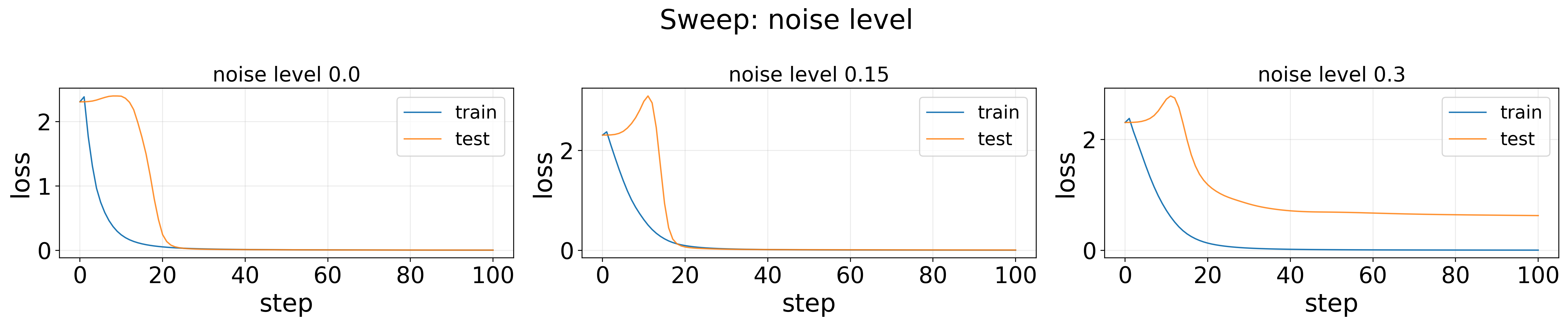
For noise level = 0.0 or 0.15, loss curves clearly show delayed generalization. When noise level = 0.3, the newtork fails to perfectly generalize in the end. For noise level = 0.15, if you zoom in a bit, you would see the test loss is even lower than the train loss for some step, which is unexpected.
Sweep: noise level — Accuracy
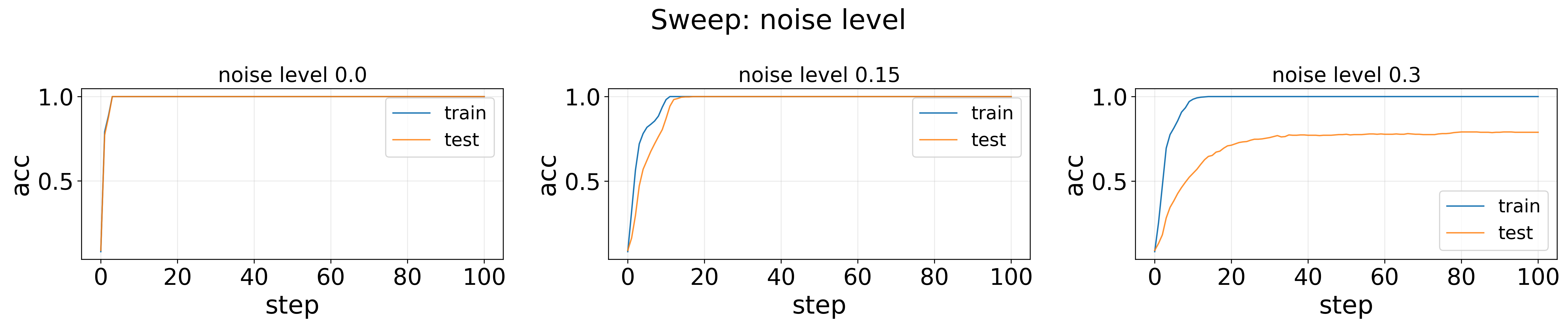
However, delayed generalization is not significant for accuracy in any case. Only noise level = 0.15 show small delayed generalization.
Code
Code can be downloaded here. (still some bug with the generated code)
Enjoy Reading This Article?
Here are some more articles you might like to read next: