Data efficiency of Bi-gram data
Black: Agent generated; Red: Added by human
Introduction
Bi-gram data is a simple dataset capturing some basic aspect of natural language. When there are \(V\) tokens in vocabulary, it is expected that at least \(V^2\) tokens should be seen to learn the bi-gram model well. As a result, I’m interested in measuring generalization gap as a function of vocabulary size and train size, as swept in this blog.
Experimental setup
Dataset: Bigram low-rank dataset
Model: MLP_token model
Optimizer: Adam
Loss: Cross-entropy loss
Observables wired to training: Observable Accuracy
Train vs test gap
Trainer: Trainer
Sweep experiments
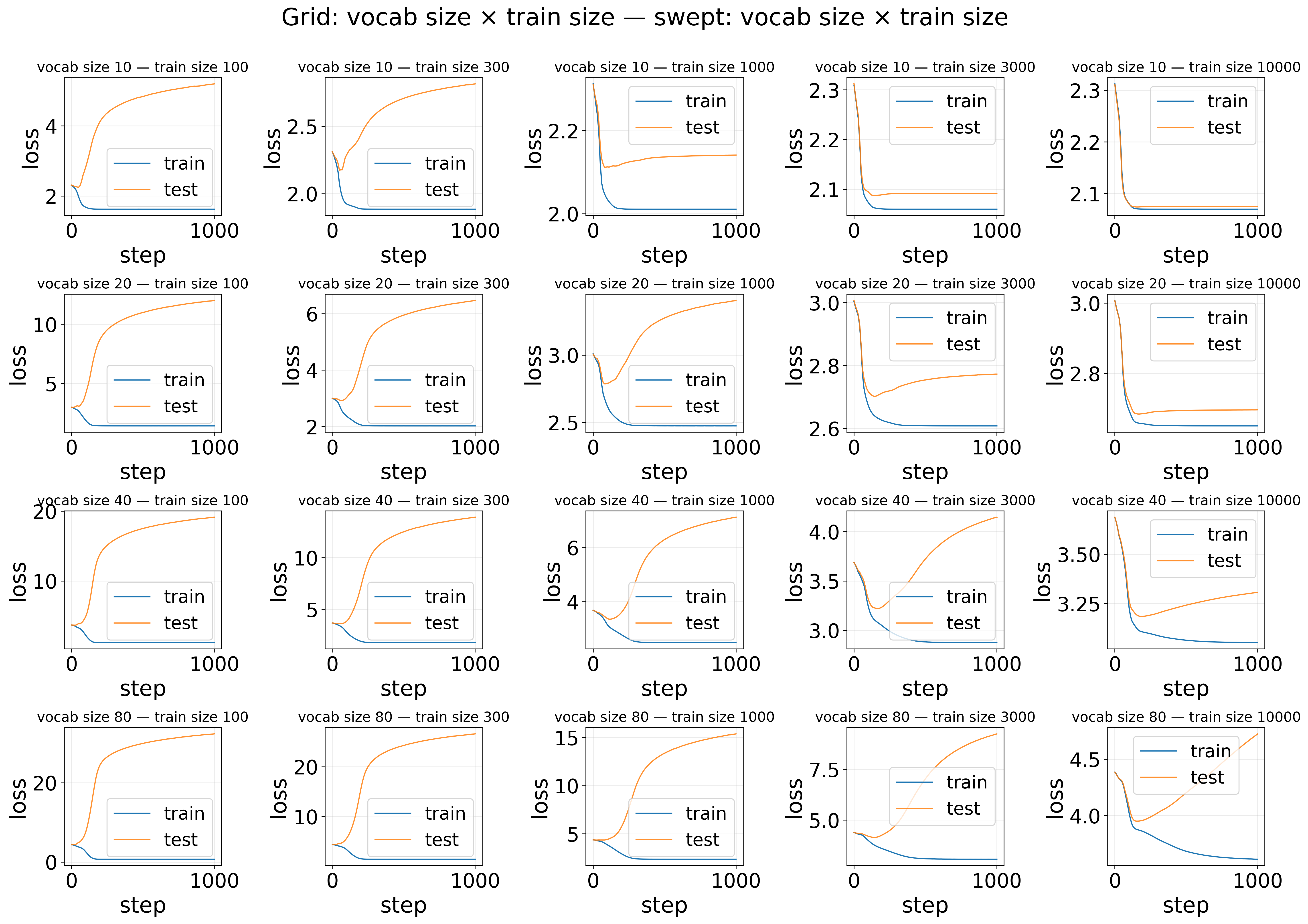
Sweep comparison — Grid: vocab size × train size — Loss
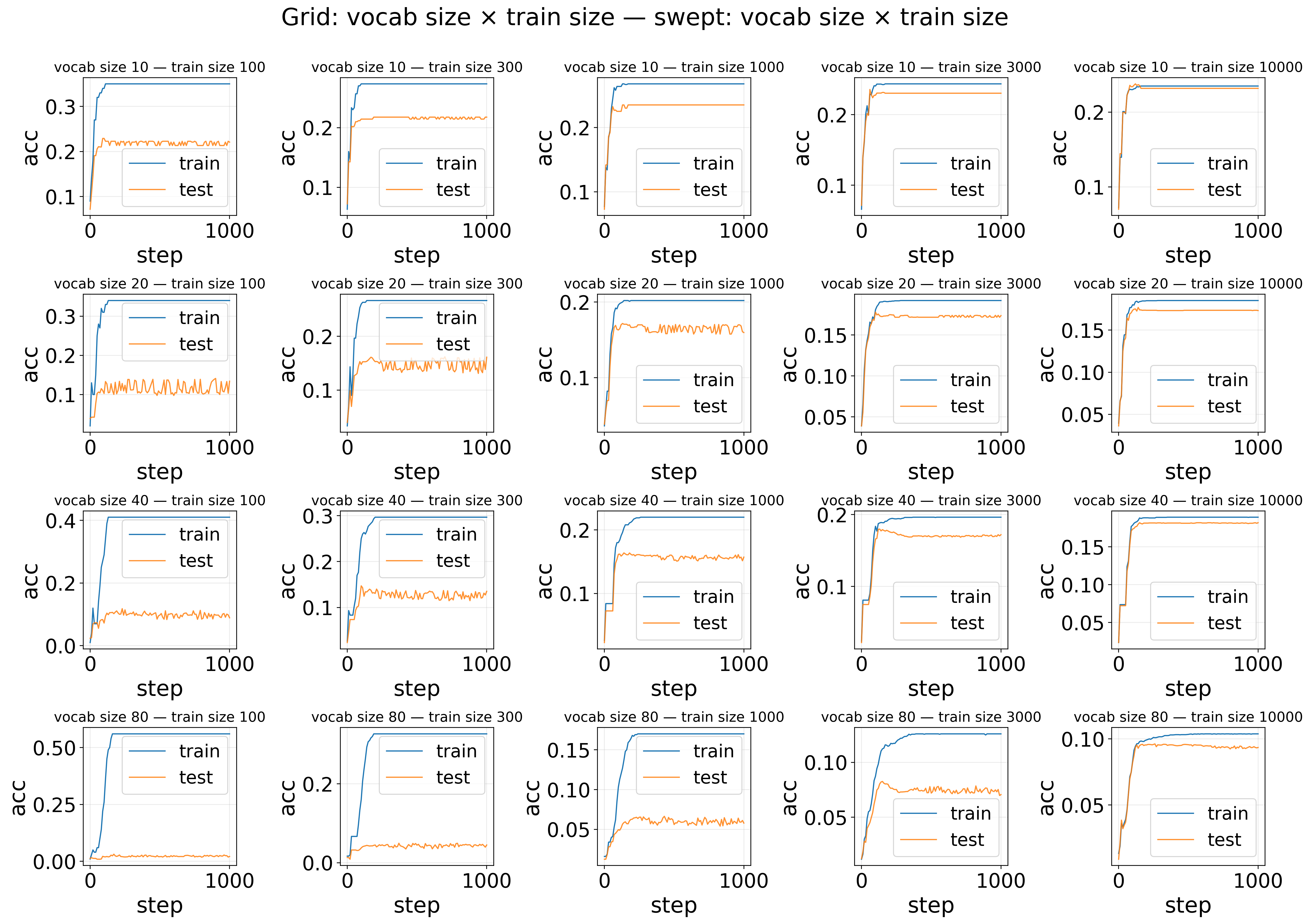
Sweep comparison — Grid: vocab size × train size — Accuracy
Sweep comparison — Grid: vocab size × train size — Train vs test gap — last step (lines)
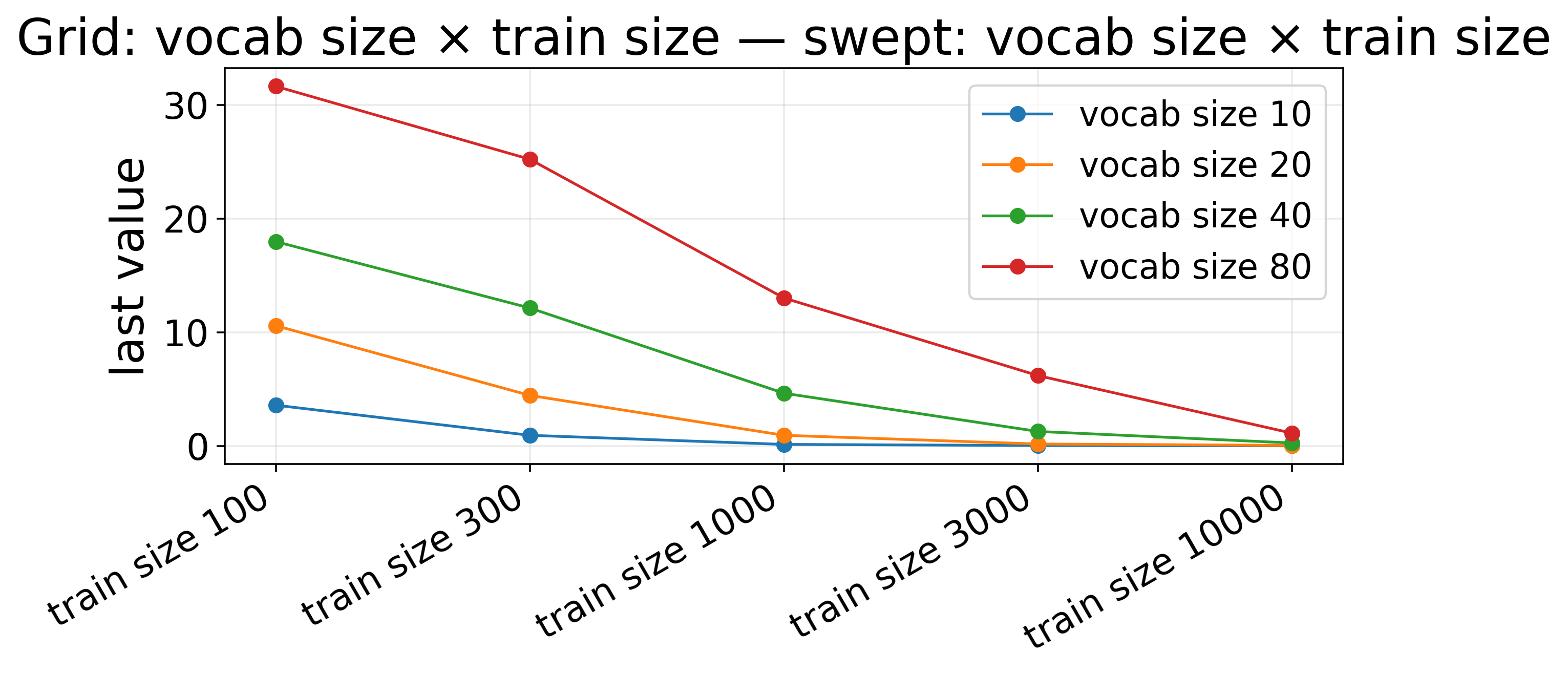
The result is expected: generalization gap (test loss minus train loss) decreases as train data increases, and larger vocabulary size requires more data. (TODO: automatic quantitative analysis)
Code
Code can be downloaded here.
Enjoy Reading This Article?
Here are some more articles you might like to read next: