Interpretability 4: Feature attribution
How to determine the importance of features? This is known as feature attribution. This notebook shows how to get feature scores in KANs.
from kan import *
from sympy import *
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# let's construct a dataset
f = lambda x: x[:,0]**2 + 0.3*x[:,1] + 0.1*x[:,2]**3 + 0.0*x[:,3]
dataset = create_dataset(f, n_var=4, device=device)
input_vars = [r'$x_'+str(i)+'$' for i in range(4)]
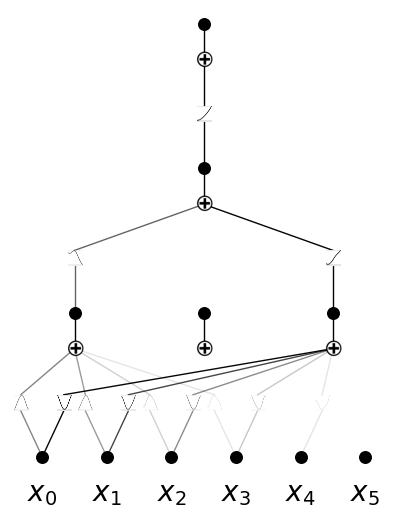
model = KAN(width=[4,5,1], device=device)
model.fit(dataset, steps=40, lamb=0.001);
cuda
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 8.00e-03 | test_loss: 8.47e-03 | reg: 4.61e+00 | : 100%|█| 40/40 [00:07<00:00, 5.20it
saving model version 0.1
model.plot()
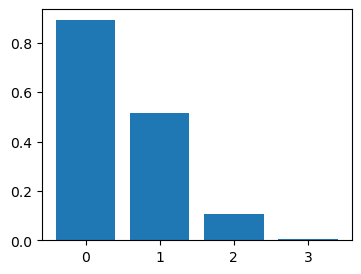
get feature score (for input variables)
model.feature_score
tensor([0.8916, 0.5155, 0.1079, 0.0040], device='cuda:0',
grad_fn=<MeanBackward1>)
Inspect how hidden nodes depend on features
# the 2nd neuron (index start from 0) in the 1st layer
model.attribute(1,2)
tensor([0.8915, 0.5146, 0.1079, 0.0040], device='cuda:0',
grad_fn=<SelectBackward0>)
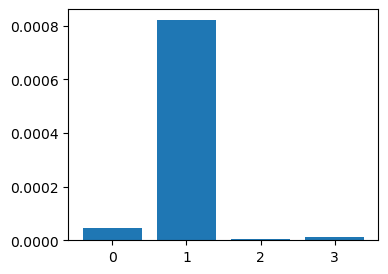
# the 3nd neuron (index start from 0) in the 1st layer
# note the y axis scale is really small
model.attribute(1,3)
tensor([4.6616e-05, 8.2072e-04, 3.2453e-06, 1.3511e-05], device='cuda:0',
grad_fn=<SelectBackward0>)
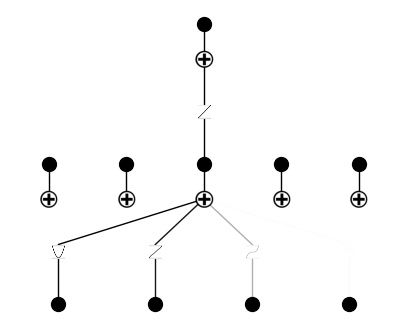
prune inputs
model = model.prune_input()
model.plot(in_vars=input_vars)
keep: [True, True, True, False]
saving model version 0.2
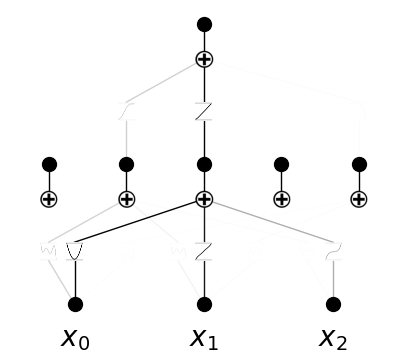
Let’s consider a high-dimensional case. In the case of many inputs but only few are important, the users may want to prune input otherwise too many inputs make interpretable hard.
from kan import *
# let's construct a dataset
n_var = 100
def f(x):
y = 0
for i in range(n_var):
# exponential decay
y += x[:,[i]]**2*0.5**i
return y
dataset = create_dataset(f, n_var=n_var, device=device)
input_vars = [r'$x_{'+str(i)+'}$' for i in range(n_var)]
model = KAN(width=[n_var,10,10,1], seed=2, device=device)
model.fit(dataset, steps=50, lamb=1e-3);
checkpoint directory created: ./model
saving model version 0.0
| train_loss: 3.20e-02 | test_loss: 5.46e-02 | reg: 1.71e+01 | : 100%|█| 50/50 [00:16<00:00, 3.12it
saving model version 0.1
model.plot()
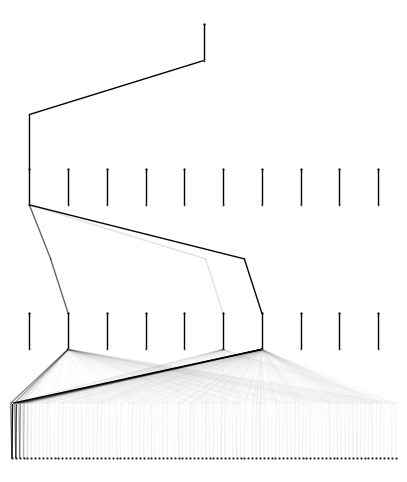
model = model.rewind('0.1')
rewind to model version 0.1, renamed as 1.1
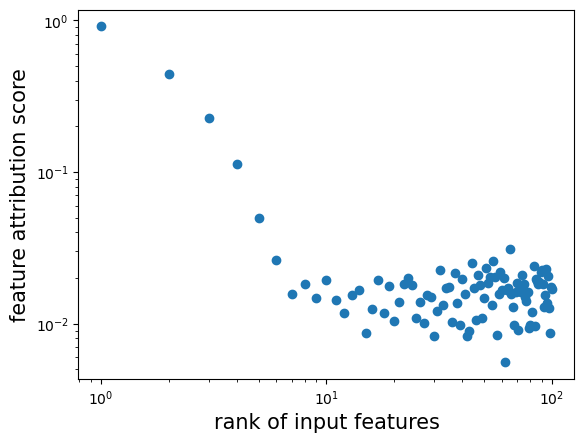
plt.scatter(np.arange(n_var)+1, model.feature_score.cpu().detach().numpy())
plt.xscale('log')
plt.yscale('log')
plt.xlabel('rank of input features', fontsize=15)
plt.ylabel('feature attribution score', fontsize=15)
Text(0, 0.5, 'feature attribution score')
Since there are 100D inputs, it’s very time consuming to plot the whole diagram and hard to read anything meaningful out of the diagram. So we want to prune the network first (including pruning hidden nodes and pruning inputs) and then plot it.
model = model.prune()
model = model.prune_input(threshold=3e-2)
model.plot(in_vars=input_vars)
saving model version 1.2
keep: [True, True, True, True, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False, False]
saving model version 1.3